PCA¶
Let for be random vectors with means and variance matrix . Consider finding , a dimensional vector with so that is maximized. Notice this is equivalent to saying we want to maximize . The well known solution to this equation is that is the first eigenvector of and is the associated eigenvalue. If is the eigenvalue decomposition of where are the eigenvectors and is a diagonal matrix of the eigenvalues ordered from greatest to least, then corresponds to the first column of and corresponds to the first element of . If one then finds as the vector maximizing so that , then the are the columns of and are the eigenvalues.
Notice:
(i.e. diagonalizess )
(i.e. the total variability is the sum of the eigenvalues)
Since , is a rotation matrix. Thus, rotates in such a way that to maximize variability in the first dimension, then the second dimensions ...
if
Another representation of is by simply rewriting the matrix algebra of .
The variables then: have uncorrelated elements ( for by property 5), have the same total variability as the elements of ( by property 2), are a rotation of the , are ordered so that has the greatest amount of variability and so on.
Notation:
The are simply called the eigenvalues or principal components variation.
is called the principal component scores.
The are called the principal component loadings or weights, with being called the first principal component and so on.
Statistical properties under the assumption that the are iid with mean 0 and variance
if
.
Sample PCA¶
Of course, we’re describing PCA as a conceptual process. We realize dimensional vectors to , typically organized in a matrix. If is not mean 0, we typically demean it by calculating where is a vector of ones. Assume this is done. Then . Thus, our sample PCA is obtained via the eigenvalue decomposition and our principal components obtained as .
We can relate PCA to the SVD as follows. Let be the SVD of the scaled version of . Then note that
yields the sample covariance matrix eigenvalue decomposition.
PCA with a large dimension¶
Consider the case where one of or is large. Let’s assume is large. Then
As we learned in the chapter on HDF5, we can do sums like these without loading the entirety of into memory. Thus, in this case, we can calculate the eigenvectors using only the small dimension. If, on the other hand, is large and is smaller, then we can calculate the eigenvalue decomposition of
In either case, whether or is easier to get, we can then obtain the other via vectorized multiplication.
Simple example¶
## If you need to install the dependencies that aren't normally part of colab
#!pip install audio2numpy &> /dev/null
#!pip install medmnist &> /dev/nullimport numpy as np
import matplotlib.pyplot as plt
import numpy.linalg as la
from sklearn.decomposition import PCA
import urllib.request
import PIL
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import torch.utils.data as data
from torch.utils.data import TensorDataset, DataLoader
from sklearn.decomposition import FastICA
from tqdm import tqdm
import medmnist
from medmnist import INFO, Evaluator
import scipy
import IPython
import audio2numpy as a2n
n = 1000
mu = (0, 0)
Sigma = np.array([[1, .5], [.5, 1]])
X = np.random.multivariate_normal( mean = mu, cov = Sigma, size = n)
plt.scatter(X[:,0], X[:,1]);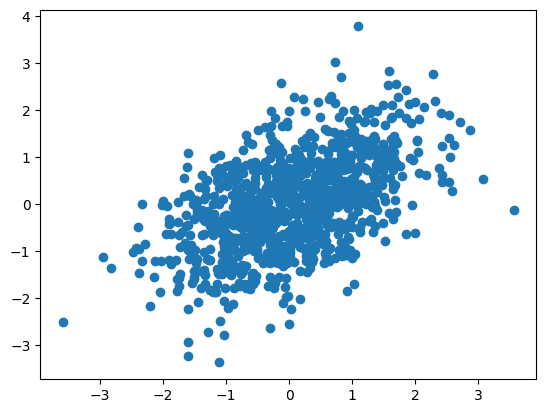
X = X - X.mean(0)
print(X.mean(0))
Sigma_hat = np.matmul(np.transpose(X), X) / (n-1)
Sigma_hat[7.32747196e-18 3.84137167e-17]
array([[1.02255046, 0.52537753],
[0.52537753, 0.99663657]])evd = la.eig(Sigma_hat)
lambda_ = evd[0]
v_hat = evd[1]
u_hat = np.matmul(X, np.transpose(v_hat))
plt.scatter(u_hat[:,0], u_hat[:,1]);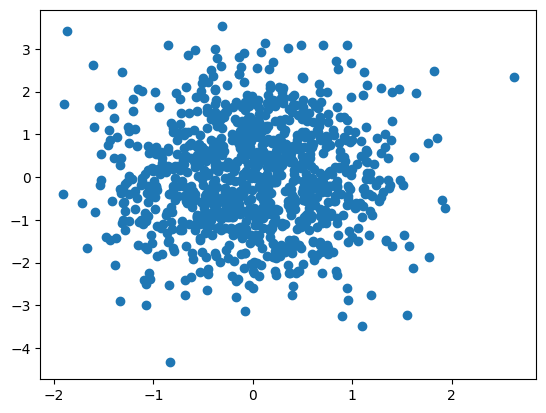
Fit using scikitlearn’s function
pca = PCA(n_components = 2).fit(X)
print(pca.explained_variance_)
print(lambda_ )[1.53513079 0.48405623]
[1.53513079 0.48405623]
Example¶
Let’s consider the melanoma dataset that we looked at before. First we read in the data as we have done before so we don’t show that code.
data_flag = 'dermamnist'
## This defines our NN parameters
NUM_EPOCHS = 10
BATCH_SIZE = 128
lr = 0.001
info = INFO[data_flag]
task = info['task']
n_channels = info['n_channels']
n_classes = len(info['label'])
##https://github.com/MedMNIST/MedMNIST/blob/main/examples/getting_started.ipynb
data_flag = 'dermamnist'
data_transform = transforms.Compose([
transforms.ToTensor()
])
DataClass = getattr(medmnist, info['python_class'])
# load the data
train_dataset = DataClass(split = 'train', transform = data_transform, download = True)
test_dataset = DataClass(split = 'test' , transform = data_transform, download = True)
pil_dataset = DataClass(split = 'train', download = True)
train_loader = data.DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = data.DataLoader(dataset=test_dataset, batch_size=2*BATCH_SIZE, shuffle=False)Downloading https://zenodo.org/records/10519652/files/dermamnist.npz?download=1 to /root/.medmnist/dermamnist.npz
100%|██████████| 19725078/19725078 [00:02<00:00, 9532838.96it/s]
Using downloaded and verified file: /root/.medmnist/dermamnist.npz
Using downloaded and verified file: /root/.medmnist/dermamnist.npz
Next, let’s get the data from the torch dataloader format back into an image array and a matrix with the image part (28, 28, 3) vectorized.
def loader_to_array(dataloader):
## Read one iteration to get data
test_input, test_target = next(iter(dataloader))
## Total number of training images
n = np.sum([inputs.shape[0] for inputs, targets in dataloader])
## The dimensions of the images
imgdim = (test_input.shape[2], test_input.shape[3])
images = np.empty( (n, imgdim[0], imgdim[1], 3))
## Read the data from the data loader into our numpy array
idx = 0
for inputs, targets in dataloader:
inputs = inputs.detach().numpy()
for j in range(inputs.shape[0]):
img = inputs[j,:,:,:]
## get it out of pytorch format
img = np.transpose(img, (1, 2, 0))
images[idx,:,:,:] = img
matrix = images.reshape(n, 3 * np.prod(imgdim))
idx += 1
return images, matrix
train_images, train_matrix = loader_to_array(train_loader)
test_images, test_matrix = loader_to_array(test_loader)
## Demean the matrices
train_mean = train_matrix.mean(0)
train_matrix = train_matrix - train_mean
test_mean = test_matrix.mean(0)
test_matrix = test_matrix - test_meanNow let’s actually perform PCA using scikitlearn. We’ll plot the eigenvalues divided by their sums, . This is called a scree plot.
from sklearn.decomposition import PCA
n_comp = 10
pca = PCA(n_components = n_comp).fit(train_matrix)
plt.plot(pca.explained_variance_ratio_);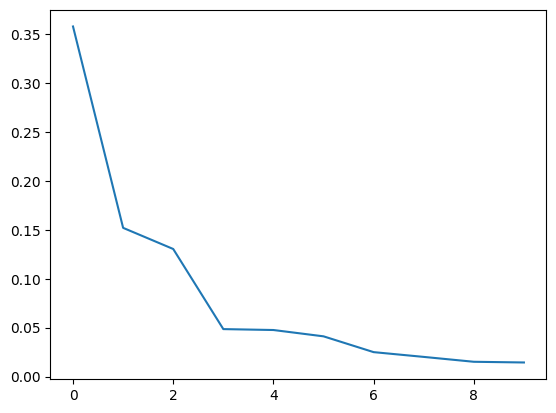
Often this is done by plotting the cummulative sum so that you can visualize how much variance is explained by including the top components. Here I fit 10 components and they explain 85% of the variation.
plt.plot(np.cumsum(pca.explained_variance_ratio_));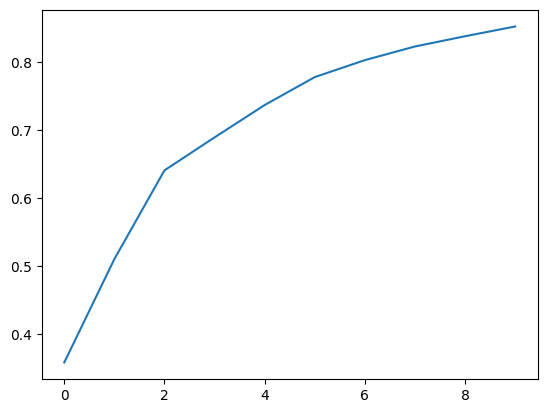
Note that the weights from the eigenvectors, , are images. We can plot these as images.
eigen_moles = pca.components_plt.figure(figsize=(10,5))
for i in range(10):
plt.subplot(2, 5,i+1)
plt.xticks([])
plt.yticks([])
img = eigen_moles[i,:].reshape(28, 28, 3)
img = (img - img.min())
img = img / img.max()
img = img * 255
img = img.astype(np.uint8)
plt.imshow(img)
Let’s project our testing data onto the principal component basis created by our training data and see how it does. Let is the SVD of our training data. Then, we can convert ths scores, back to with the map . Or, if our scores are normalized, then we simply multiply by . If we want to represent by a lower dimensional summary, we just keep fewer columns of scores, then multiply by the same columns of . We could write this as , where refers to a subset of values of .
Notice that , and . Consider then an approximation to as . Written otherwise
which is the projection of subject ’s features into the linear space spanned by the basis defined by the principal component loadings.
Let’s try this on our mole data.
test_matrix_fit = pca.inverse_transform(pca.transform(test_matrix))
np.mean(np.abs( test_matrix - test_matrix_fit))0.03792390874027308test_matrix_fit_remeaned = test_matrix_fit + test_mean
test_matrix_remeaned = test_matrix + test_mean
plt.figure(figsize=(10,5))
for i in range(5):
plt.subplot(2, 5,i+1)
plt.xticks([])
plt.yticks([])
img = test_matrix_remeaned[i,:].reshape(28, 28, 3)
img = (img - img.min())
img = img / img.max()
img = img * 255
img = img.astype(np.uint8)
plt.imshow(img)
plt.subplot(2, 5,i+6)
plt.xticks([])
plt.yticks([])
img = test_matrix_fit_remeaned[i,:].reshape(28, 28, 3)
img = (img - img.min())
img = img / img.max()
img = img * 255
img = img.astype(np.uint8)
plt.imshow(img)
ICA¶
ICA, independent components analysis, tries to find linear transformations of the data that are statistically independent. Usually, independence is an assumption in ICA, not actually embedded in the loss function.
Let be an collection of source signals. Assume that the underlying signals are independent, so that . Assume that the observed data is and . It is typically assumed that is invertible so that and and are called the mixing and unmixing matrices respectively. Note that, since we observe over many repititions of , we can get an estimate of . Typically, it is also assumed that the are iid over .
One way to characterize the estimation problem is to parameterize , and and use maximum likelihood, or equivalent [citations]. Another is to minimize some distance between and , and . Yet another is to actually maximize independence between the components of using some estimate of independence [cite Matteson].
The most popular approaches try to find by maximizing non-Gaussianity. The logic goes that 1) interesting features tend to be non-Gaussian and 2) an appeal to the CLT over signals suggest that the mixed signals should be more Gaussian by being linear combinations of independent things. The latter claim is heuristic relative to the formal CLT. However, maximizing non-Gaussian components tends to work well in practice, thus validating the motivation empirically.
One form of ICA maximizes the kurtosis. If is a random variable, then is the kurtosis. One could then find that maximizes the empirical kurtosis of the unmixed signals. Another variation of non-Gaussianity maximizes neg-entropy. The neg-entropy of a density is given by
A well known theorem states that the Gaussian distribution has the largest entropy of all distributions with the same variance. Therefore, to maximize non-Gaussianity, we can minmize entropy, or equivalently maximize neg-entropy. We could subtract the entropy of the Gaussian distribution to consider this a cross entropy problem, but that only adds a constant to the loss function. The maximization of neg-entropy can be done many ways. We need the following. For a given , estimate from the collection , then calculate the neg-entropy of . Use that to then take an opimization step of is the right direction. Some versions of estimation use a polynomial expansion of the , which then typically only requires higher order moments, like kurtosis. Fast ICA is a particular implmementation of maximizing neg-entropy.
Statistical versions of ICA don’t require to be invertible. Moreover, error terms can be added in which case you can see the connection between ICA and factor analytic models. However, factor analysis models tend to assume Gaussianity.
Example¶
Consider an example that PCA would have somewhat of a hard time with. In this case, our data is from a mixture of normals with half from a normal with a strong positive correlation and half with a strong negative correlation. Because the angle between the two is not 90 degrees PCA has no chance. No rotation of the axes satisfies the obvious structure in this data.
n = 1000
Sigma = np.array([[4, 1.8], [1.8, 1]])
a = np.random.multivariate_normal( mean = [0, 0], cov = Sigma, size = int(n/2))
Sigma = np.array([[4, -1.8], [-1.8, 1]])
b = np.random.multivariate_normal( mean = [0, 0], cov = Sigma, size = int(n/2))
x = np.append( a, b, axis = 0)
plt.scatter(x[:,0], x[:,1])
plt.xlim([-6, 6])
plt.ylim([-6, 6])(-6.0, 6.0)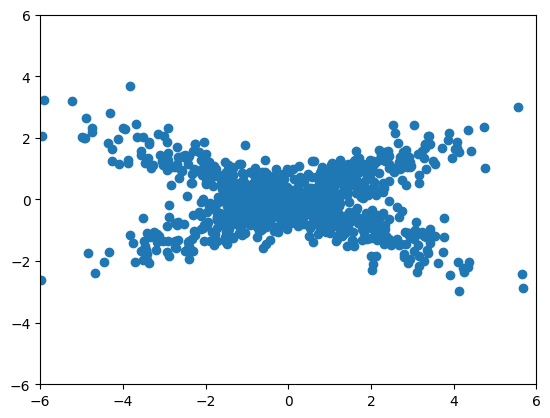
Let’s try fast ICA. Notice it comes much closer to discovering the structure we’d like to discover than PCA could. It pulls appart the two components to a fair degree. Also note, there’s a random starting point of ICA, so that I get fairly different fits over re-runs of the algorithm. I had to lower the tolerance to get a good fit.
Indpendent components are order invariant and sign invariant.
transformer = FastICA(tol = 1e-7)
icafit = transformer.fit(x)
s = icafit.transform(x)
plt.scatter(s[:,0], s[:,1])
plt.xlim( [s.min(), s.max()])
plt.ylim( [s.min(), s.max()])/usr/local/lib/python3.10/dist-packages/sklearn/decomposition/_fastica.py:128: ConvergenceWarning: FastICA did not converge. Consider increasing tolerance or the maximum number of iterations.
warnings.warn(
(-4.7190845526356995, 4.268426740921572)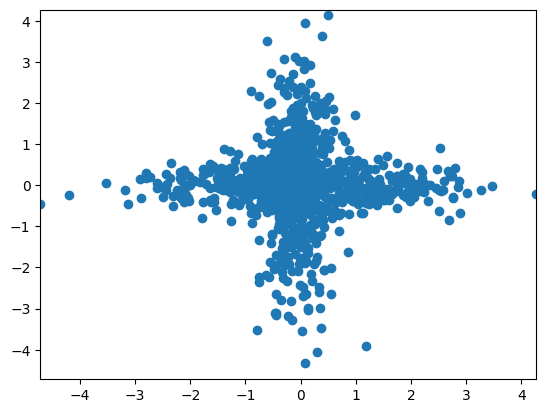
Cocktail party example¶
The classic ICA problem is the so called cocktail party problem. In this, you have sources and microphones. The microphones each pick up a mixture of signals from the different sources. The goal is to unmix the sources into the components. Independence makes sense in the cocktail party example, since logically conversations would have some independence.
## If you need to get the files if running on colab this
## puts them in the same relative spot as the github directory
#!mkdir assetts
#!mkdir assetts/mp3s
#%cd assetts/mp3s
#!wget https://github.com/smart-stats/ds4bio_book/raw/refs/heads/main/book/assetts/mp3s/4.mp3 &> /dev/null
#!wget https://github.com/smart-stats/ds4bio_book/raw/refs/heads/main/book/assetts/mp3s/2.mp3 &> /dev/null
#!wget https://github.com/smart-stats/ds4bio_book/raw/refs/heads/main/book/assetts/mp3s/6.mp3 &> /dev/null
#%cd ../..
## So annoying, I misspelled assets but now there's too many things linking
## to it to change
s1, i1 = a2n.audio_from_file("assetts/mp3s/4.mp3")
s2, i2 = a2n.audio_from_file("assetts/mp3s/2.mp3")
s3, i3 = a2n.audio_from_file("assetts/mp3s/6.mp3")
## Get everything to be the same shape and sum the two audio channels
n = np.min((s1.shape[0], s2.shape[0], s3.shape[0]))
s1 = s1[0:n,:].mean(axis = 1)
s2 = s2[0:n,:].mean(axis = 1)
s3 = s3[0:n,:].mean(axis = 1)
s = np.array([s1, s2, s3])IPython.display.Audio(s1, rate = i1)IPython.display.Audio(s2, rate = i1)IPython.display.Audio(s3, rate = i1)Mix the signals.
w = np.array( [ [.7, .2, .1], [.1, .7, .2], [.2, .1, .7] ])
x = np.transpose(np.matmul(w, s))Here’s an example mixed signal
IPython.display.Audio(data = x[:,1].reshape(n), rate = i1)Now try to unmix using fastICA
transformer = FastICA(whiten='unit-variance', tol = 1e-7)
icafit = transformer.fit(x)icafit.mixing_Unmixing matrix
icafit.components_array([[14.83234064, -4.14317395, -1.06280459],
[-1.8715552 , -0.32901438, 6.94242909],
[-1.18667626, 17.11366031, -4.77739855]])Here’s a scatterplot matrix where the real component is on the rows and the estimated component is on the columns.
hat_s = np.transpose(icafit.transform(x))
plt.figure(figsize=(10,10))
for i in range(3):
for j in range(3):
plt.subplot(3, 3, (3 * i + j) + 1)
plt.scatter(hat_s[i,:].squeeze(), np.asarray(s)[j,:])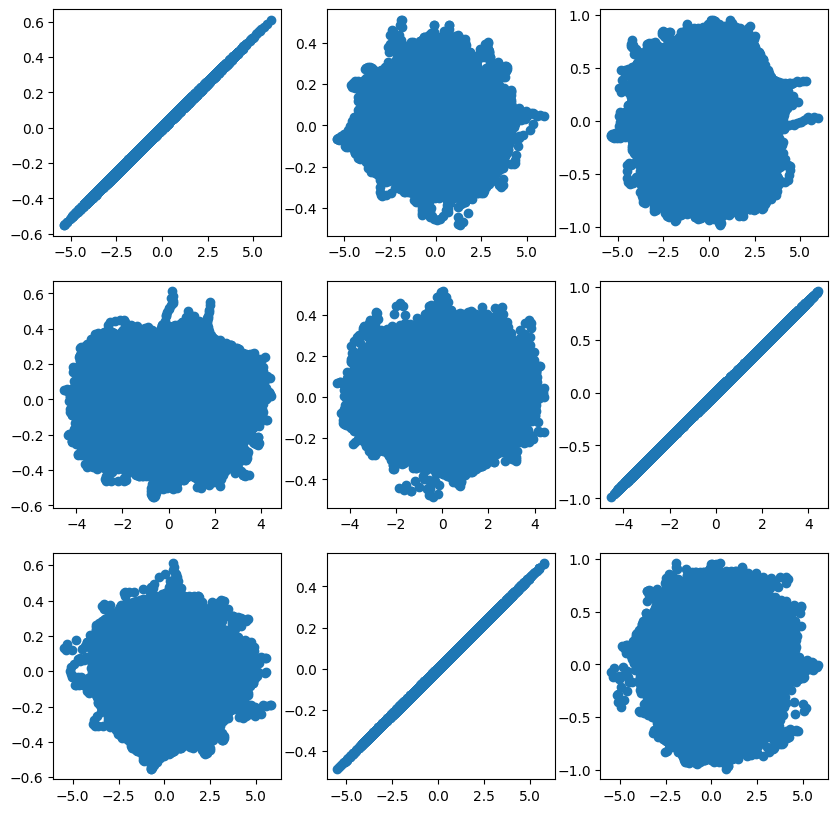
We can now play the estimated sources and see how they turned out.
from scipy.io.wavfile import write
i = 0
data = (hat_s[i,:].reshape(n) / np.max(np.abs(hat_s[i,:]))) * .5
IPython.display.Audio(data = data, rate = i1)i = 1
data = (hat_s[i,:].reshape(n) / np.max(np.abs(hat_s[i,:]))) * .5
IPython.display.Audio(data = data, rate = i1)i = 2
data = (hat_s[i,:].reshape(n) / np.max(np.abs(hat_s[i,:]))) * .5
IPython.display.Audio(data = data, rate = i1)Imaging example using ICA¶
Let’s see what we get for the images. Logically, one would consider voxels as mixed sources and images as the iid replications. But, then the sources would not be images. Let’s try the other dimension and see what we get where subject images are mixtures of source images. This is analogous to finding a soure basis of subject images.
This is often done in ICA where people transpose matrices to investigate different problems.
transformer = FastICA(n_components=10, random_state=0,whiten='unit-variance', tol = 1e-7)
icafit = transformer.fit_transform(np.transpose(train_matrix))
icafit.shape/usr/local/lib/python3.10/dist-packages/sklearn/decomposition/_fastica.py:128: ConvergenceWarning: FastICA did not converge. Consider increasing tolerance or the maximum number of iterations.
warnings.warn(
(2352, 10)train_matrix_remeaned = train_matrix + train_mean
plt.figure(figsize=(10,5))
for i in range(10):
plt.subplot(2, 5,i+1)
plt.xticks([])
plt.yticks([])
img = icafit[:,i].reshape(28, 28, 3)
img = (img - img.min())
img = img / img.max()
img = img * 255
img = img.astype(np.uint8)
plt.imshow(img)