Repeatability or test/retest reliabity is the agreement of measurements across technical replications.
12.1.1 Mean/difference - Bland/Altman plots
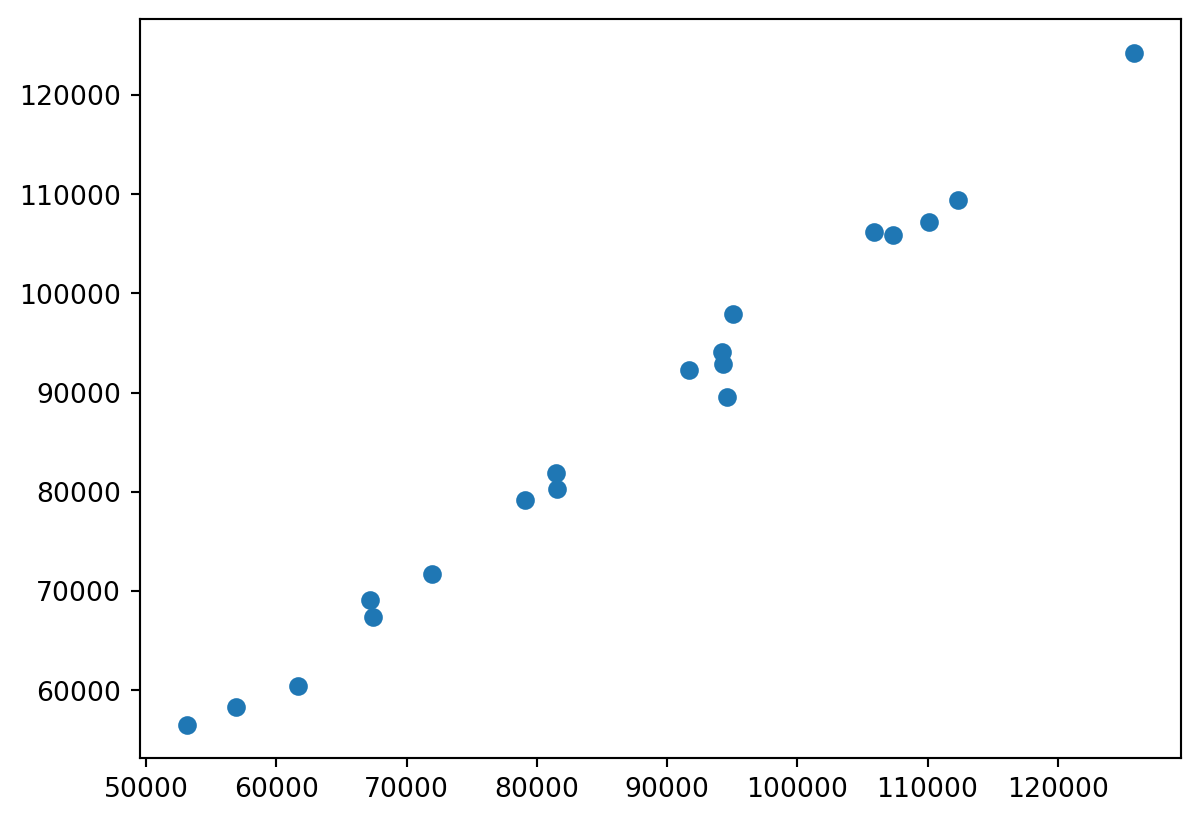
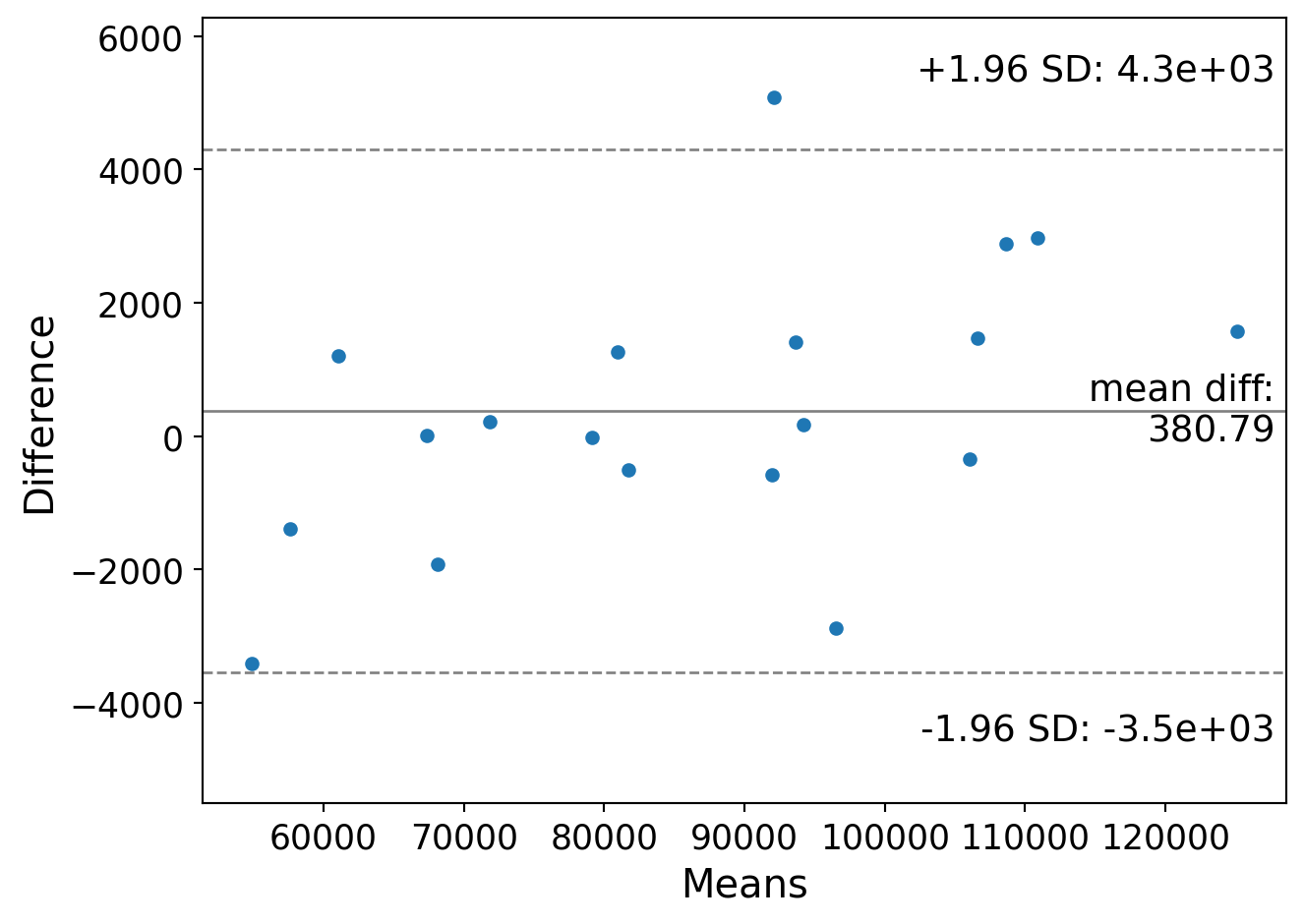
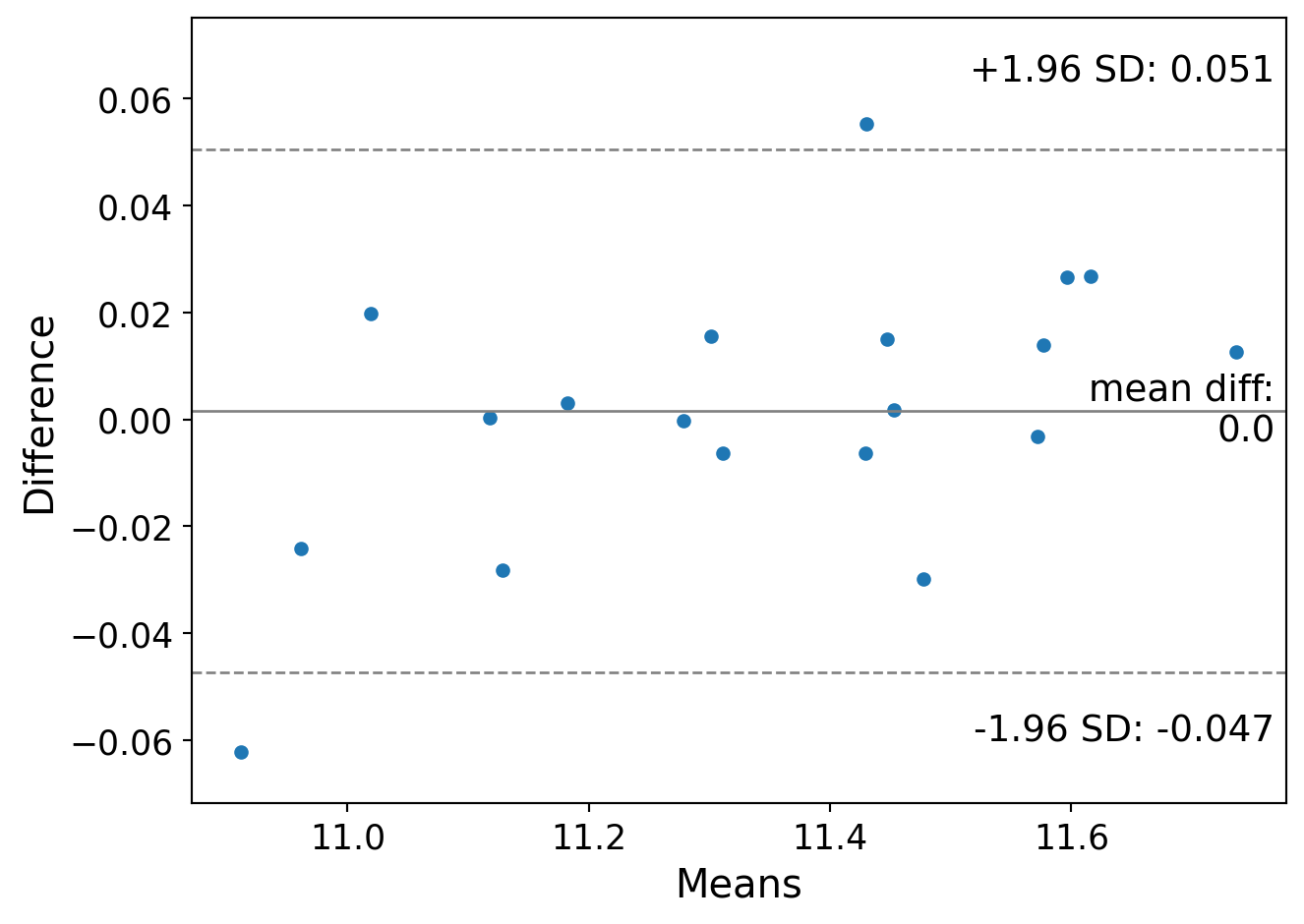
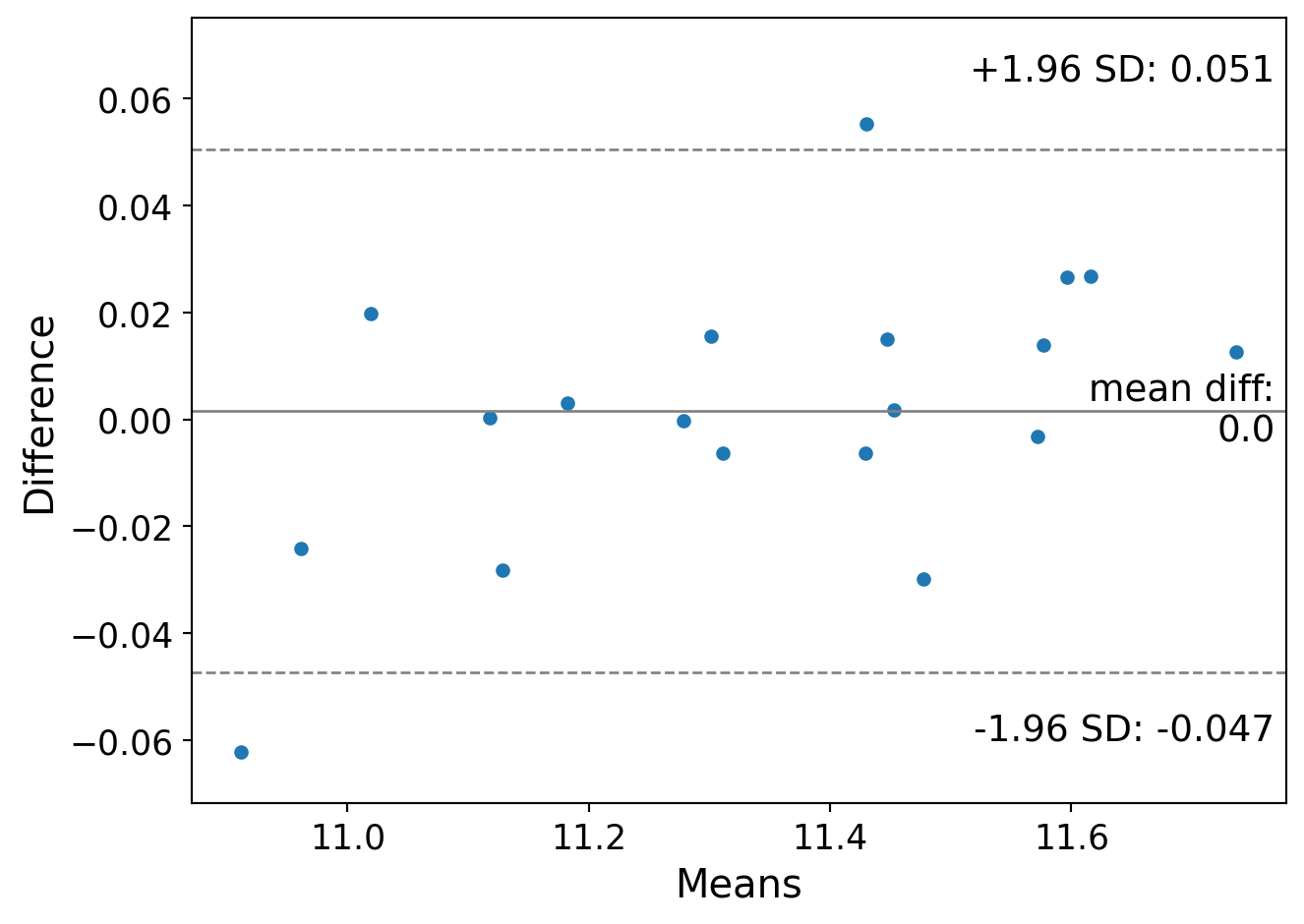
The Bland/Altman (Bland and Altman 1999) or Tukey mean/difference plot (Tukey et al. 1977) is a plot of agreement between two measured quantities. Here I use the mricloudpy package to read in data and convert it to a dataframe. Here, we have two measures of the same data. B/A plots typically add a 1.96 sd bar to detect outlying differences.
import statsmodels.api as smimport numpy as npimport sys import ossys.path.append("/home/bcaffo/sandboxes/MRICloudPy/mricloudpy/")from mricloudpy.mricloudpy import Dataexample ="/home/bcaffo/sandboxes/MRICloudPy/mricloudpy/sample_data/"d = Data(example)
import_data: Data files found
['/home/bcaffo/sandboxes/MRICloudPy/mricloudpy/sample_data/kirby127a_3_1_ax_283Labels_M2_corrected_stats.txt', '/home/bcaffo/sandboxes/MRICloudPy/mricloudpy/sample_data/kirby142a_3_1_ax_283Labels_M2_corrected_stats.txt', '/home/bcaffo/sandboxes/MRICloudPy/mricloudpy/sample_data/kirby239a_3_1_ax_283Labels_M2_corrected_stats.txt', '/home/bcaffo/sandboxes/MRICloudPy/mricloudpy/sample_data/kirby346a_3_1_ax_283Labels_M2_corrected_stats.txt', '/home/bcaffo/sandboxes/MRICloudPy/mricloudpy/sample_data/kirby422a_3_1_ax_283Labels_M2_corrected_stats.txt', '/home/bcaffo/sandboxes/MRICloudPy/mricloudpy/sample_data/kirby492a_3_1_ax_283Labels_M2_corrected_stats.txt', '/home/bcaffo/sandboxes/MRICloudPy/mricloudpy/sample_data/kirby501a_3_1_ax_283Labels_M2_corrected_stats.txt', '/home/bcaffo/sandboxes/MRICloudPy/mricloudpy/sample_data/kirby505a_3_1_ax_283Labels_M2_corrected_stats.txt', '/home/bcaffo/sandboxes/MRICloudPy/mricloudpy/sample_data/kirby656a_3_1_ax_283Labels_M2_corrected_stats.txt', '/home/bcaffo/sandboxes/MRICloudPy/mricloudpy/sample_data/kirby679a_3_1_ax_283Labels_M2_corrected_stats.txt', '/home/bcaffo/sandboxes/MRICloudPy/mricloudpy/sample_data/kirby742a_3_1_ax_283Labels_M2_corrected_stats.txt', '/home/bcaffo/sandboxes/MRICloudPy/mricloudpy/sample_data/kirby800a_3_1_ax_283Labels_M2_corrected_stats.txt', '/home/bcaffo/sandboxes/MRICloudPy/mricloudpy/sample_data/kirby814a_3_1_ax_283Labels_M2_corrected_stats.txt']
import_data: Importing...
The intra-class correlation coefficient is a measure of agreement. It measures the ratio of the inter-subject variation to the total variation (intra and inter). I like to think of ICC as a random effect model. If \(Y_{ij}\) is measurement \(j\) on subject \(i\) then consider the random effect model
Note, this ICC model applies even if there’s more than 2 measurements per subject.
Consider two subjects, however. There’s an easy moment estimator in that \[
Y_{i2} - Y_{i1} = \epsilon_{i2} - \epsilon_{i1}
\] Thus, the variance of the differences is an estimator of $2^2. Similarly, \[
(Y_{i1} + Y_{i2})/2 = U_i + (\epsilon_{i2} + \epsilon_{i1})/2.
\] Thus, the variance of the average is an estimate of \(\sigma_u^2 + \sigma^2 / 4\). Thus, we have two equations and two uknowns. This solution has the benefit that it doesn’t depend on the normality of the random effects. However, it can produce negative estimates. Another approach simply uses maximum likelihood.