
![]()
Regression and FFTs#
Recall regression through the origin. If \(y\) and \(x\) are \(n\)-vectors of the same length, the minimizer of
is \(\hat \beta = <x, y> / ||x||^2\). Note, if \(||x|| = 1\) then the estimate is just \(\hat \beta = <x, y>\). Now consider a second variable, \(w\), such that \(<x, w> = 0\) and \(||w|| = 1\). Consider now the least squares model
We argued that the best estimate for \(\beta\) now first gets rid of \(w\) be regressing it out of \(y\) and \(x\). So, consider that
Thus, now the best estimate of \(\beta\) is
Or, in other words, if \(x\) and \(w\) are orthogonal then the coefficient estimate for \(x\) with \(w\) included is the same as the coefficient of \(x\) by itself. This extends to more than two regressors.
If you have a collection of \(n\) mutually orthogonal vectors of norm one, they are called an orthonormal basis. For an orthonomal basis, 1. the coefficients are just the inner products between the regressors and the outcome and 2. inclusion or exclusion of other elemenents of the basis doesn’t change a basis elements estimated coefficients.
It’s important to note, that this works quite generally. For example, for complex numbers as well as real. So, for example, consider the possibility that \(x\) is \(e^{-2\pi i m k / n}\) for \(m=0,\ldots, n-1\) for a particular value of \(k\). Vectors like this are orthogonal for different values of \(k\) and all have norm 1. We have already seen that the Fourier coefficient is
where \(y_m\) is element \(m\) of \(y\). Thus, the Fourier coefficients are exactly just least squares coefficients applied in the complex space. Thus we have that
where \(a_k\) and \(b_k\) are the coefficients from linear models with just the sine and cosine terms. Of course, we don’t actually fit Fourier transforms this way, since there’s a much faster way to do, aptly named the fast Fourier transform (FFT). However, knowing how fast discrete Fourier transforms relate to linear models allows us to use them in creative ways, like putting them into models with other covariates, or in logistic regression models.
Let’s numerically look at FFTs and linear models using covid case counts in Italy as an example.
import pandas as pd
import numpy as np
from sklearn import linear_model
import matplotlib.pyplot as plt
import statsmodels.api as sm
dat = pd.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')
dat.head()
| Province/State | Country/Region | Lat | Long | 1/22/20 | 1/23/20 | 1/24/20 | 1/25/20 | 1/26/20 | 1/27/20 | ... | 2/28/23 | 3/1/23 | 3/2/23 | 3/3/23 | 3/4/23 | 3/5/23 | 3/6/23 | 3/7/23 | 3/8/23 | 3/9/23 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NaN | Afghanistan | 33.93911 | 67.709953 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 209322 | 209340 | 209358 | 209362 | 209369 | 209390 | 209406 | 209436 | 209451 | 209451 |
| 1 | NaN | Albania | 41.15330 | 20.168300 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 334391 | 334408 | 334408 | 334427 | 334427 | 334427 | 334427 | 334427 | 334443 | 334457 |
| 2 | NaN | Algeria | 28.03390 | 1.659600 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 271441 | 271448 | 271463 | 271469 | 271469 | 271477 | 271477 | 271490 | 271494 | 271496 |
| 3 | NaN | Andorra | 42.50630 | 1.521800 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 47866 | 47875 | 47875 | 47875 | 47875 | 47875 | 47875 | 47875 | 47890 | 47890 |
| 4 | NaN | Angola | -11.20270 | 17.873900 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 105255 | 105277 | 105277 | 105277 | 105277 | 105277 | 105277 | 105277 | 105288 | 105288 |
5 rows × 1147 columns
## Get Italy, drop everyrthing except dates, convert to long (unstack converts to tuple)
y=dat[dat['Country/Region'] == 'Italy'].drop(["Province/State", "Country/Region", "Lat", "Long"], axis=1).unstack()
## convert from tuple to array
y = np.asarray(y)
## get case counts instead of cumulative counts
y = y[1 : y.size] - y[0 : (y.size - 1)]
## get the first non zero entry
y = y[np.min(np.where(y != 0)) : y.size]
plt.plot(y)
[<matplotlib.lines.Line2D at 0x7c2219af5750>]
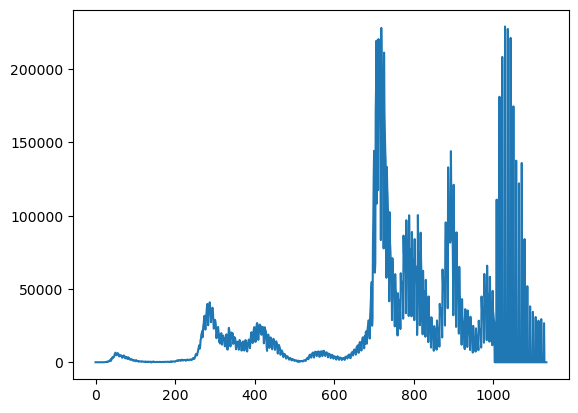
Let’s look at a smoothed version of it and then take the residual. The residual is where we’d like to look at some oscillatory behavior.
n = y.size
t = np.arange(0, n, 1)
lowess = sm.nonparametric.lowess
yhat = lowess(y, t, frac=.05,return_sorted=False)
plt.plot(y)
plt.plot(yhat)
[<matplotlib.lines.Line2D at 0x7c22116ef730>]
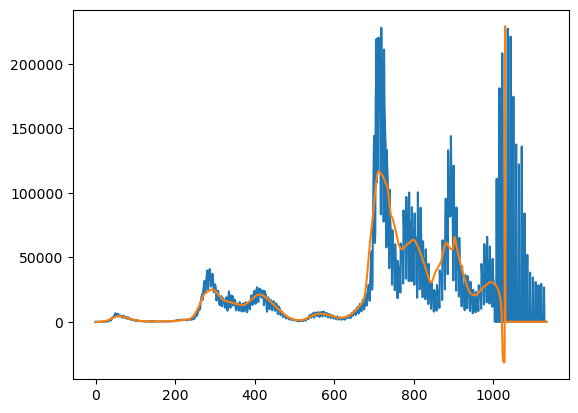
## We're interested in the residual
e = y - yhat
plt.plot(e)
[<matplotlib.lines.Line2D at 0x7c22117678b0>]
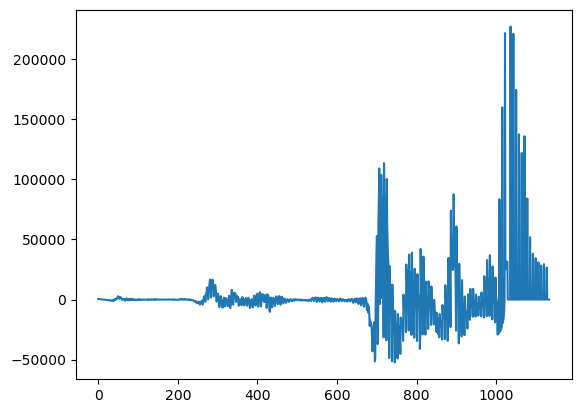
Let’s manually create our Fourier bases. We’re just going to pick some periods to investigate. We’ll pick a fast varying and slow varying.
## Create 4 elements
## Orthonormal basis (note dividing by sqrt(n/2) makes them norm 1)
c5 = np.cos(-2 * np.pi * t * 5 / n ) / np.sqrt(n /2)
c20 = np.cos(-2 * np.pi * t * 20 / n ) / np.sqrt(n /2)
s5 = np.sin(-2 * np.pi * t * 5 / n )/ np.sqrt(n /2)
s20 = np.sin(-2 * np.pi * t * 20 / n ) / np.sqrt(n /2)
fig, axs = plt.subplots(2, 2)
axs[0,0].plot(t, c5)
axs[0,1].plot(t, c20)
axs[1,0].plot(t, s5)
axs[1,1].plot(t, s20)
plt.show()
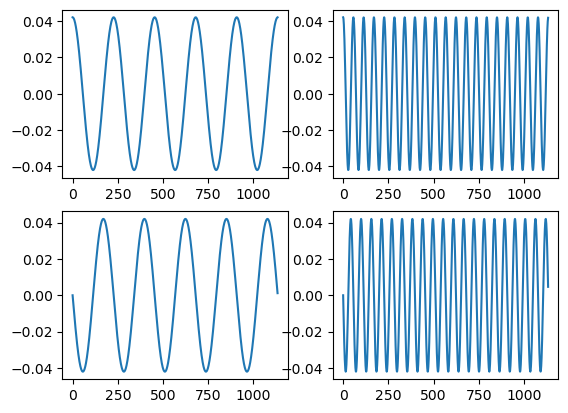
Let’s verify that they are indeed orthonormal. That is, we want to show that \(<x_i, x_j> = I(i =j)\). We also show that they are all mean 0.
## Verify that they are orthonormal mean 0, round to 6 decimal places
np.around( [
np.sum(c5),
np.sum(c20),
np.sum(s5),
np.sum(s20),
np.sum(c5 * c5),
np.sum(c20 * c20),
np.sum(s5 * s5),
np.sum(s20 * s20),
np.sum(c5 * s5),
np.sum(c5 * s20),
np.sum(c5 * c20),
np.sum(s5 * s20),
], 6)
array([-0., 0., 0., -0., 1., 1., 1., 1., 0., 0., -0., -0.])
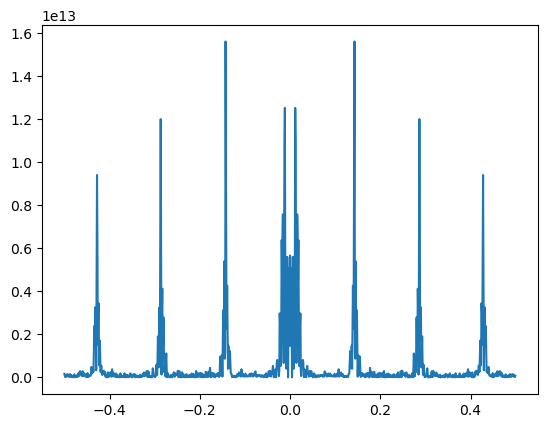
Let’s take the FFT, the fast (discrete) Fourier transform th way one would normally do it. First, we use FFT in numpy. Then, there’s a convenient method, fftfreq, which gives the associated frequencies with each element of the transform. Finally, we plot the spectral density, which is the sum of the real and complex Fourier coefficients. Sorting the elements first is necessary to connect the dots on the plot. Interestingly, once we remove the trend from the Italy data, there’s some very noticeable spikes in the spectral density, which implies large coefficients on that specific frequency. This is possibly some reporting issue.
f = np.fft.fft(e)
w = np.fft.fftfreq(n)
ind = w.argsort()
f = f[ind]
w = w[ind]
plt.plot(w, f.real**2 + f.imag**2)
[<matplotlib.lines.Line2D at 0x7c2211523fa0>]
Now let’s manually find the coefficients using our constructed bases and the formula that the coefficients.
[
np.sum(c5 * e) * np.sqrt(n / 2),
np.sum(c20 * e) * np.sqrt(n / 2),
np.sum(s5 * e) * np.sqrt(n / 2),
np.sum(s20 * e) * np.sqrt(n / 2),
]
[-42402.16539776623, -961069.7936856844, 62406.76098672958, 1902286.8621751775]
sreg = linear_model.LinearRegression()
x=np.c_[c5, c20, s5, s20]
fit = sreg.fit(x, y)
fit.coef_ * np.sqrt(n/2)
array([ 1222376.2412703 , -1286448.11961955, -4881386.48874237,
1827887.03044428])
x=np.c_[c5, s5]
fit = sreg.fit(x, y)
fit.coef_ * np.sqrt(n/2)
array([ 1222376.2412703 , -4881386.48874237])
test = np.where( np.abs(f.real / np.sum(c5 * y) / np.sqrt(n / 2) - 1) < 1e-5)
[test, f.real[test], w[test], 5 / n]
[(array([], dtype=int64),),
array([], dtype=float64),
array([], dtype=float64),
0.004409171075837742]
f.imag[test]
array([], dtype=float64)